
Kubernetes is an open-source tool donated by Google after experiencing it for over 10 years as
Borg. It is a platform to work with containers and is an orchestration framework for containers that give you: deployment, scaling,
monitoring & health checks of containers. What Kubernetes cannot do is - it cannot provide CI/CD thus companies have to choose, which tool is a better fit in their architecture, since there are many opensource/CNCF tool available for it.
K8s help in moving from host-centric infrastructure to container-centric infrastructure
Key things to remember  |
In the virtualization world - the atomic unit of scheduling is VM, same way in docker its Container, and in Kubernetes it is Pod
|
Kubernetes comprises of control plane a.k.a master node & worker nodes.
we define our application requirement in k8s yaml's
In k8s we enforce desired state management via a manifest.yaml file. That's where we feed the cluster service to run on the desired state in our infrastructure.
Pods running in the k8s cluster cannot be exposed directly it has to be via service.
All objects in Kubernetes are persistent.
Understand Kubernetes in
5 mins
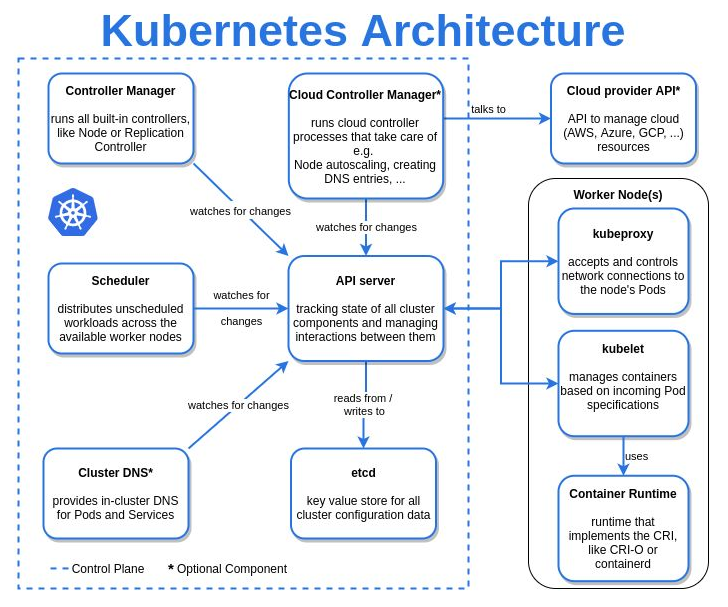 |
| Kubernetes Architecture in detail |
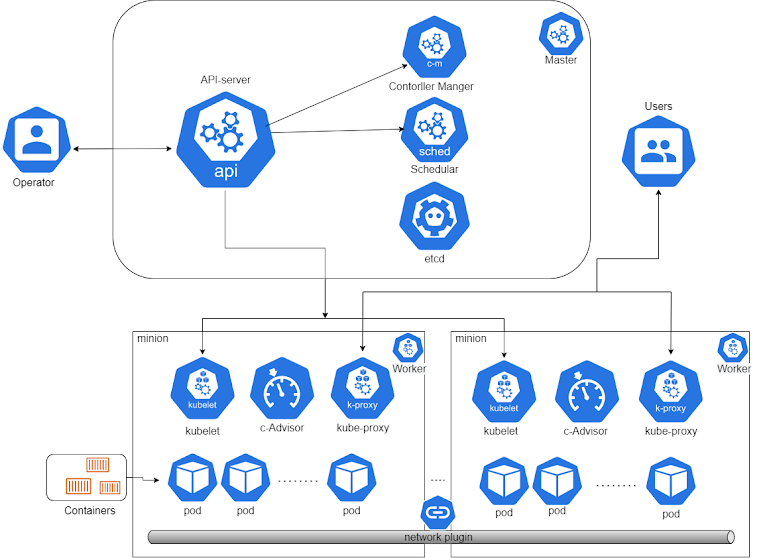 |
Kubernetes Architecture flow diagram
|
Native objects in Kubernetes
 Control Plane/Master Node
Control Plane/Master Nodemaster machine in the Kubernetes cluster
kube-api-server − This is an API that can be used to orchestrate the Docker containers.
etcd − k8s objects persist here. This component is a highly available key-value store used to hold and manage the critical information that distributed systems need to keep running. Most notably, it manages the configuration data, state data, and metadata for Kubernetes, here the various applications will be able to connect to the services via the discovery service.
kube-scheduler − This is used to schedule the newly created pods to nodes. Determines where workloads should run.
Controller-manager - monitors the state of a cluster & take action to ensure the actual state matches the desired state by communicating with the API server to initiate these actions.
Cloud-controller-manager* - Runs controller that interacts with the underline cloud provider & links cluster to a cloud provider's API
CoreDNS - CoreDNS is a DNS server container that's often used to support the service discovery function in containerized environments. To install CoreDNS as the default DNS service while installing a fresh Kubernetes cluster use -
$ kubeadm init --feature-gates CoreDNS=true
Data Plane/Worker Nodes
worker machines in the Kubernetes cluster
 minion
minion − is the node on which all the services run. You can have many minions running at one point in time. Each minion will host a service or application pod.
Kubelet − This is used to control the launching of containers via manifest files from the worker host.
Container runtime - is responsible for downloading images and running them. other than docker podman and cri-o are the other two container runtimes k8s can use.
kube-proxy − is used to provide network proxy services that allow communication to the pod & to the outside world.
basic objects in Kubernetes
which talks with the API server ensuring the pods and their associated containers are running.
Pod − Pods are Mortal & is the smallest unit of deployment in K8s object mode or is like hosting a service. Each POD can host a different set of Docker containers. The proxy is then used to control the exposure of these services to the outside world. You cannot create your own pods, they are created by replicasets.
Labels − use labels in your deployment manifest to target specific pods. that means pod with specific labels will only be manipulated depending on the label you have defined in your deployment manifest.
Flannel − This is a back-end network that is required for the nodes. It manages an IPv4 network between multiple nodes in a cluster. It does not control how containers are networked to the host, only how the traffic is transported between hosts.
ReplicaSet − replicasets are created by deployments, these deployments contain a declaration of containers that you want to run in a cluster. It uses a template that dictates how to create the newly desired pod.
Deployment - it runs multiple replicas of your application preferably for stateless applications.
DaemonSet - ensures that all Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
Advanced resources
context - it is a group of access parameters. Each context contains a Kubernetes cluster, a user, and a namespace. The current context is the cluster that is currently the default for kubectl: all kubectl commands run against that cluster. Kubernetes cheatsheet ConfigMap - an API object that let you store your other object or application configuration, setting connection strings, analytics keys, and service URLs & further mounting them in volumes to use them as an environment variable & it is reusable across deployments.
sidecar - is just a container that runs in the same Pod as the application container, because it shares the same volume and network as the main container, it can “help” or enhance how the application operates. Common examples of sidecar containers are log shippers, log watchers, monitoring agents, aka utility containers. Ex - Istio
helm − helm is a package manager for k8s which allows to package, configure & deploy applications & services to k8s-cluster.
helm Chart − helm packages are called charts, consisting of few YAML configs and some templates that are cooked into k8s manifest file.
helm chart repository − these packaged charts brought available and can be downloaded from chart repos.
Mandatory Fields while writing a manifest file
In the manifest file for Kubernetes objects you want to create, you’ll need to set values for the following fields:
kind - What kind of object you want to create.
metadata - Data that helps uniquely identify the object, including a name string, UID, and optional namespace
spec - What state you desire for the object.
Service in Kubernetes
There are four ways to make a service accessible externally in the Kubernetes cluster
- Nodeport: deployment that needs to be exposed as a service to the outside world can be configured with the NodePort type. In this method when deployment exposed, the cluster node opens a random port between default range: 30000-32767 on the node itself with IP (hence this name was given) and redirects traffic received on that random port to the underlying service endpoint which got generated when you expose your deployment. (combination of NodeIP + Port is NodePort ) accessing your app/svc as http://public-node-ip:nodePort
- clusterIP is the default and most basic, which give service its own IP and is only reachable within the cluster.
- Loadbalancer: an extension of the NodePort type—This makes the service accessible through a dedicated load balancer, provisioned from the cloud infrastructure Kubernetes is running on. The load balancer redirects traffic to the node port across all the nodes. Clients connect to the service through the load balancer’s IP.
- Ingress resource, a radically different mechanism for exposing multiple services through a single IP address. It operates at the HTTP level (network layer 7) and can thus offer more features than layer 4 services can.
Network in Kubernetes
Kubernetes default ethernet adapter is called cbr0 like you have docker0 for docker.
3 fundamental requirements in the k8s networking model:
- All the containers can communicate with each other directly without NAT.
- All the nodes can communicate with all containers (and vice versa) without NAT.
- The IP that a container sees itself as is the same IP that others see it as.
Pods Networks
Implemented by CNI plugins like - calico, weave etc.
pod network is big and flat.
you have IP/Pod.
every pod can talk to any other pod via cni plugins.
Nodes Networks
All nodes need to be able to talk
kubelet <-> API Server
Every node on the n/w has this process running called Kubeproxy & kubelet
n/w not implemeneted by k8s.
Service Networks
IP of your service is not tied up with any interface
Kube-proxy in IPVS modes create a dummy interface on the service n/w, called kube-ipvs0
whereas kube-proxy in IPTABLES mode does not.
Storage in Kubernetes
there are three types of access mode:
RWO : Read Write Once - only one pod in a cluster can access this volume
RWM : Read Write Many - All pods in a cluster can access data from this volume
ROM : Read Only Many - All pods in a cluster can only read data from this volume
Not all volume support all modes
to claim the storage 3 properties has to match between PersistentVolume & PersistentVolumeClaim
1. accessMode
2. storageClassName
3. capacity
After you create the persistentVolume & persistentVolumeClaim, the Kubernetes control plane looks for a PersistentVolume that satisfies the claim's requirements. If the control plane finds a suitable PersistentVolume with the same StorageClass, it binds the claim to the volume.
as of now the pv is not claimed by any pvc and thus is available and waiting for a pvc to claim it.
after you deploy the persistentVolume(pv) & persistentVolumeClaim (pvc) you can assign it to your running pod using below kind

---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv
spec:
accessModes:
- ReadWriteOnce
storageClassName: ssd
capacity:
storage: 10Gi
hostPath:
path: "/mnt/mydata"
...
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: ssd
capacity:
storage: 10Gi
...
Deployment in Kubernetes
Deployment is all about scaling and updating your release. You deploy your container inside a pod and scale them using
replicaSet. It is not only updating replicaSet will do the rolling update, we can add a strategy also in the deployment manifest to get the job done.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 1
its deployment manifest you need to update whenever you want to scale your application tune your number of replicaSet if you want to update the app modify your image version or anything just tweak the deployment manifest and it will redeploy your pod communicating with api-server
Autoscaling in Kubernetes
when demand goes up, spin up more Pods but not via replicaset this time. Horizontal pod autoScaler is the answer. The Kubernetes autoscaling feature is to scale up and down based on demand. This feature can be added to your deployment from the CLI by using the autoscale command or adding it into the deployment manifest.
IF
---
apiVersion: v1
kind: Deployment
metadata:
name: mydeploy
spec:
replicas: 3
...
THEN
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
namespace: myapp-ns
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mydeploy
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 50
type: Utilization...
Rolling Update in Kubernetes
ReplicaSet and autoscaling are important to minimize downtime and service interruptions. whereas rolling updates provide a way to roll out app changes in an automated and controlled fashion throughout the pods. It works with pod templates such as deployments and it allows for rollback if something goes wrong.
How do you enable Rolling updates in your application
- Add rolling update strategy to your yaml file
---
apiVersion: v1
kind: Deployment
metadata:
name: mydeploy
spec:
strategy:
type: RollingUpdate
maxUnavailable: 50%
maxSurge: 2
...
# apply the updated image
$ kubectl set image deploy/my-deploy my-deploy=registry/my-deploy:2.0
deployment.extensions/my-deploy image updated
# validate the rollout
$ kubectl rollout status deploy/my-deploy
deployment "my-deploy" successfully rolled out
# undo the rollout
$ kubectl rollout undo deploy/my-deploy
deployment.extensions/my-deploy rolled back

















